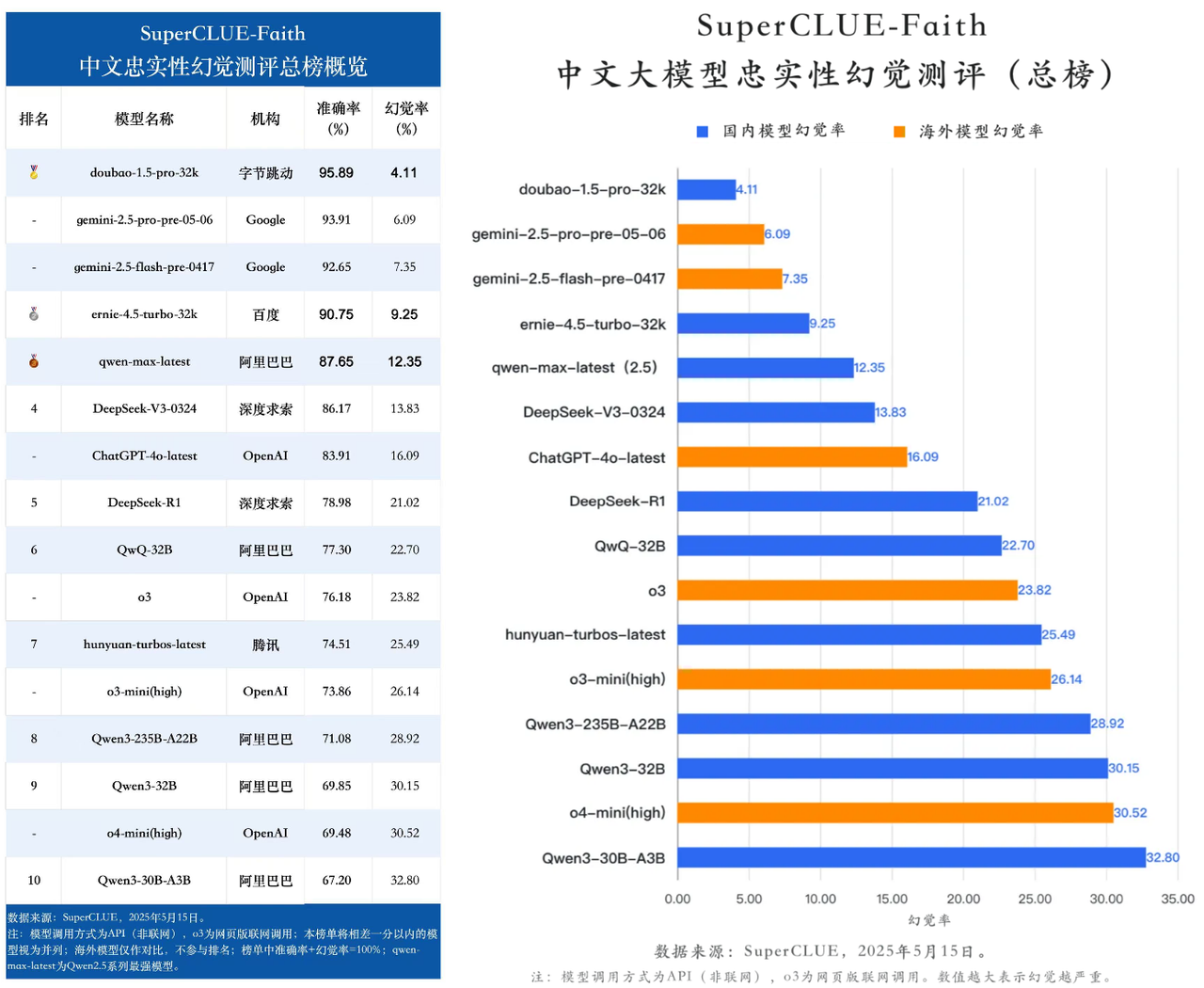
近日,根据SuperCLUE 发布的最新一轮中文大模型忠实性幻觉测评结果,豆包大模型1.5 Pro(Doubao-1.5-pro-32k)以仅4%的幻觉率、96%的准确率排名总榜第一,超越 DeepSeek-R1、DeepSeek-V3、Gemini-2.5-pro、GPT-4o-latest 等中外主流模型。
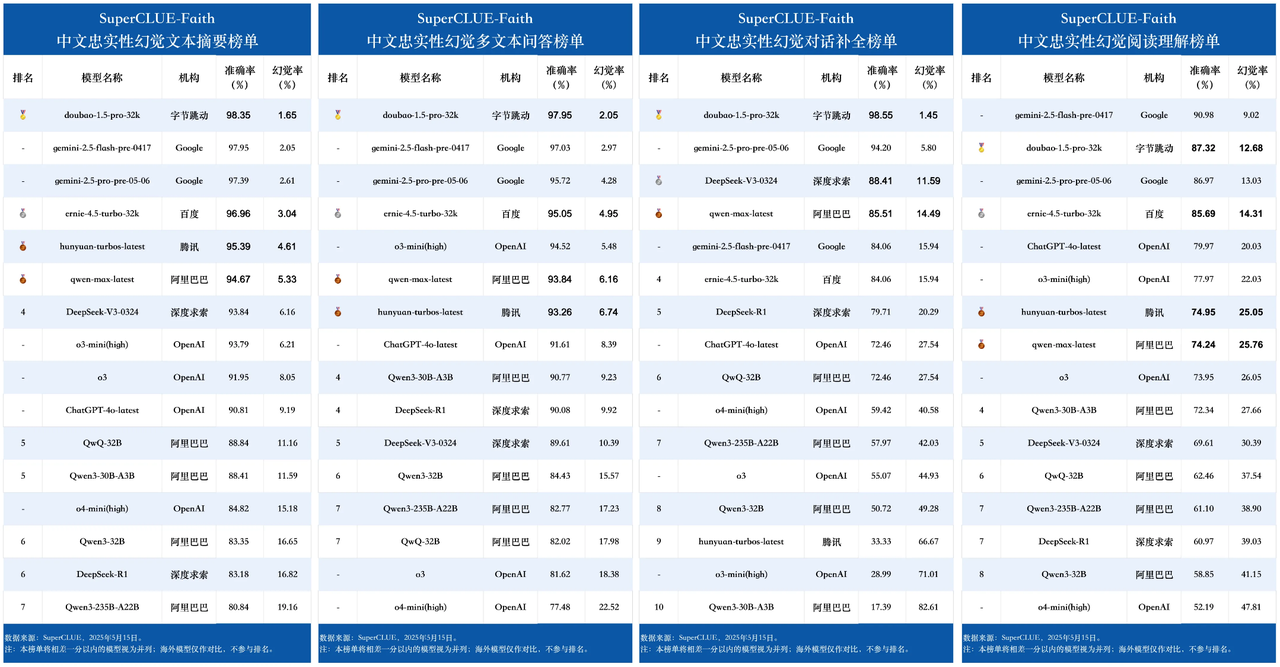
在涵盖文本摘要、多文本问答、对话补全等关键任务的细分评测中,豆包大模型1.5 Pro也均位列全球第一,在阅读理解任务中,其准确率则为国内最高,展现出在复杂语言理解与生成场景中的出色能力。
SuperCLUE 由独立第三方推出,是当前中文大语言模型评测的重要基准体系。其中 SuperCLUE-Faith 聚焦中文内容生成过程中的忠实性与幻觉控制能力,从文本摘要、阅读理解、多文本问答以及对话补全等角度展开测评,对象包括国内外共计16款具有代表性的模型,评估结果具备较强公信力与行业参考价值。
目前,豆包大模型家族已覆盖全模态、全场景,包括大语言模型、深度思考模型、视觉理解模型、语音大模型,以及图像、视频等视觉大模型,企业可以通过字节跳动旗下云服务平台火山引擎使用豆包大模型API服务。其中, 豆包大模型1.5 Pro 基于 MoE 架构构建并采用训练-推理一体化设计思路,在保证高性能的同时显著降低推理成本。通过激活有限参数实现对大规模场景的精准理解与生成,其综合性能已超过多款超大稠密预训练模型。
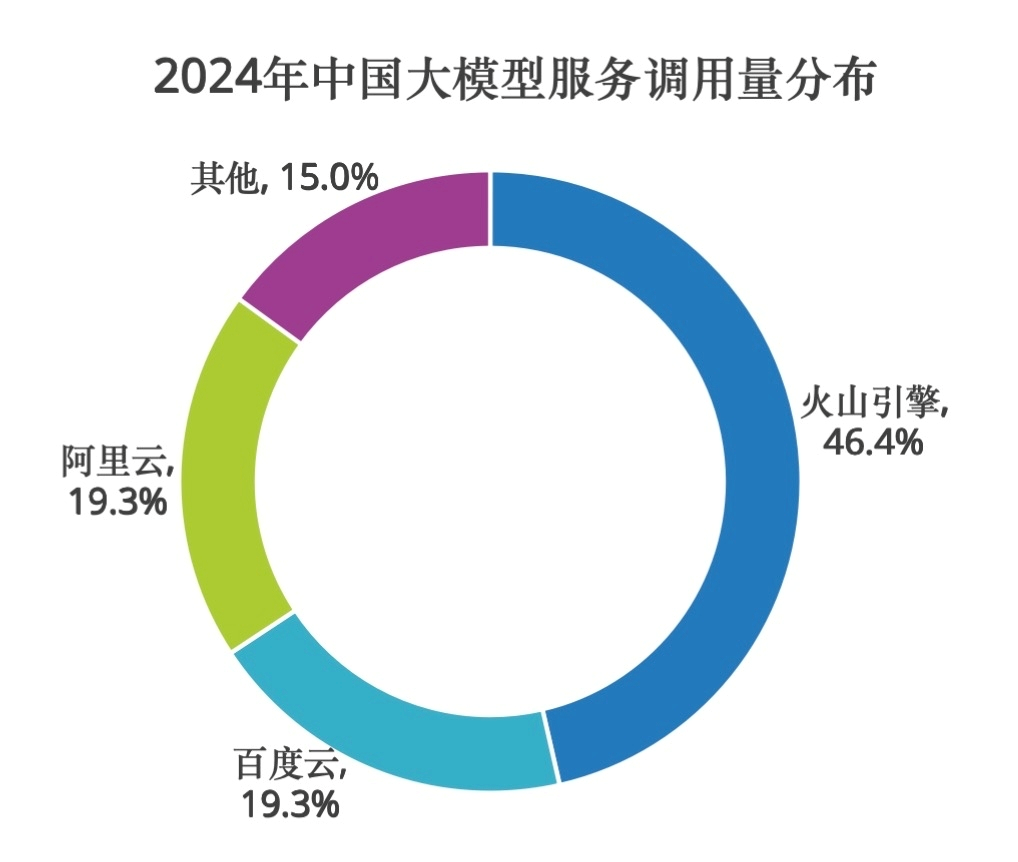
截至2025年3月底,豆包大模型日均 tokens 调用量已超过12.7万亿,是2024年12月的3倍,是一年前刚刚发布时的106倍。IDC 报告显示,2024年中国公有云大模型调用量激增,火山引擎以46.4%的市场份额位居中国市场第一。
据悉,火山引擎将于6月11日在北京举办FORCE原动力大会,将带来豆包大模型的最新升级进展与能力进化。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。